近日,数据科学与人工智能研究院人工智能研究中心的研究成果"Mono3DVLT: Monocular-Video-Based 3D Visual Language Tracking"被计算机视觉顶级会议CVPR 2025接收,标志着我校首次实现计算机视觉领域国际顶会CVPR的论文突破。CVPR是计算机视觉与模式识别领域最权威的国际顶级学术会议之一,与ICCV、ECCV并称为计算机视觉领域的国际三大顶会,是中国计算机学会(CCF)推荐的A类国际会议。
论文由数智院人工智能研究中心孙士杰副教授、宋翔宇副教授合作发表,其他作者包括:长安大学博士生魏弘凯、研究生杨洋、西安电子科技大学副教授冯明涛、墨尔本大学教授Naveed Akhtar、西澳大学教授Ajmal Saeed等,长安大学为第一作者和通讯作者单位。
该研究首次聚焦并深入研究了单目视频下的三维视觉语言跟踪难题。视觉语言跟踪(VLT)作为连接人机性能差距的新兴范式,虽在二维空间扩展了文本驱动视频理解的边界,却始终受限于三维跟踪能力的发展瓶颈。现有三维跟踪技术高度依赖点云、深度测量、雷达等昂贵传感器,且缺乏与语言描述的深度融合,严重制约了该技术在现实场景中的普及应用。针对这一挑战,研究团队开创性地提出基于单目视频的三维视觉语言跟踪框架,取得三项突破性进展:首次定义单目视频三维视觉语言跟踪(Mono3DVLT)任务范式;构建首个大规模数据集Mono3DVLT-V2X,通过大语言模型生成与人工验证相结合,为79,158段视频序列提供包含2D/3D边界框标注的自然语言描述;研发专用神经网络模型Mono3DVLT-MT,其多模态特征提取器、视觉语言编码器、跟踪解码器和跟踪头组成的创新架构,在Mono3DVLT-V2X数据集上建立性能基准。实验表明,该模型显著优于现有技术方案,为三维视觉语言跟踪领域的发展奠定重要基础。
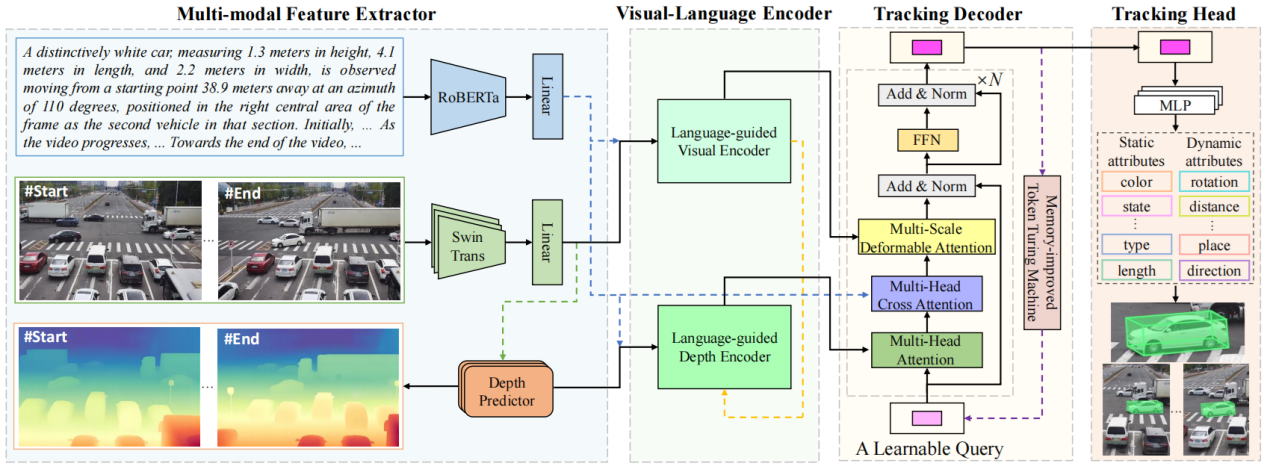
图1 Mono3DVLT框架示意图

图2 Mono3DVLT-V2X结果示例
近年来,人工智能研究中心围绕三维视觉感知、多模态智能交互、智能交通系统等方向,展开了一系列系统性研究工作,相关成果已陆续发表于ECCV、ITS、TCSVT、TPAMI等国际顶级会议和期刊,取得了学术界和工业界的广泛关注,国内外学术声誉不断提高,影响力不断扩大,为研究院的学科发展和科研团队建设做出了积极贡献。




